AI in E-Commerce : Why You're Losing Sales and How Sparse Embeddings Fix It

AI in e-commerce is redefining how customers search and shop online. This blog explores how poor search results lead to lost sales and how advanced AI models like SPLADE improve accuracy, boost conversions, and help businesses recover hidden revenue.
In the hyper-competitive world of digital retail, your search bar is either a bridge or a barrier. While most brands focus on flashy UI and social media ads, a silent revenue killer is hiding in plain sight: search results that are semantically close but technically wrong.
As global e-Commerce heads toward an $8.3 trillion valuation, the ability to match a customer’s exact intent, down to the specific gigabyte, color, and model, is no longer a luxury. It’s the difference between a completed checkout and a lost customer.
It is also the aspect where companies are acknowledging the relevance of AI in e-Commerce.
Why is E-Commerce Losing Sales?
Imagine a customer seeking an iPhone 15 Pro Max 256GB. A modern neural search bar processes the query but displays the 128GB version as the top result. Because the mathematical model identifies high semantic similarity between the two, they are the same device in different capacities, it considers the result a match.
For the customer, this is a failure. They specified a storage size for a reason. When a store fails to honor exact attributes, the likelihood of an abandoned cart skyrockets.
This is a primary failure mode documented in the Amazon Shopping Queries Dataset (ESCI). Effective implementation of AI in e-Commerce ensures these attribute-specific failures are minimized.
The Digital Retail Landscape
The e-Commerce market is projected to hit $7.9 trillion by 2027. In this shift, search functionality is the primary bridge between intent and transaction. Search visitors generate 40% to 60% of total revenue, yet fewer than 15% of companies invest significantly in optimizing this experience. This gap represents a massive opportunity for AI in e-Commerce to drive immediate ROI.
Poor search quality leads to higher return rates, suppressed organic rankings, and brand erosion. In the U.S., 94% of consumers have received irrelevant results, and 85% report that search difficulties negatively change their perception of a brand.
This report examines how sparse embeddings, specifically the SPLADE model, solve structural flaws in product search. We will analyze benchmark evidence showing a 29% lift over legacy systems and explore implementation strategies for modern retail teams. The growing role of AI in e-Commerce is reshaping how these teams prioritize search over traditional UI updates.
Three Ways Your Current Search is Failing
Most online stores operate on search foundations that are either too literal or too abstract. Legacy systems depend on exact words, while early neural systems often lose the details in a mushy middle ground of semantic similarity. The failure of AI in e-Commerce in these environments usually falls into three distinct categories.
1. Exact Attribute Blur (The Dense Embedding Problem)
Dense models compress text into fixed-size vectors (384 to 1,536 dimensions). While they excel at general concepts, they struggle with retail precision. In a dense vector space, 256GB and 128GB are mapped to nearly identical points. The system recognizes the brand but fails to distinguish the specific attribute, the storage capacity, that drives the purchase decision.
2. The Vocabulary Gap (The BM25 Problem)
BM25 scores products based on exact word frequency. If a customer searches for a summer dress but the product is listed as a sundress or floral midi, BM25 will miss it unless manual synonyms are created. Manual files cannot keep up with fluid trends like quiet luxury or cottagecore, leading to the dreaded zero results page. The evolution of AI in e-Commerce has rendered these manual lists obsolete, replacing them with dynamic, learned associations.
3. Opaque Rankings (The Interpretability Problem)
Dense embedding systems are black boxes. If a merchandising team asks why one product outranks another, there is no clear answer because the dimensions are abstract numbers. This lack of transparency makes it impossible to debug rankings or strategically adjust the search experience. Transitioning to explainable AI in e-Commerce models allows teams to regain this control.
Comparison of search architectures and the strategic placement of AI in e-Commerce solutions.
Feature | BM25 (Legacy) | Dense Embeddings (Neural) | Sparse Embeddings (SPLADE) |
|---|---|---|---|
Attribute Matching | High | Low | High |
Synonym Handling | Manual / Poor | Excellent | Excellent (Learned) |
Interpretability | High | Low | High |
Storage Type | Inverted Index | k-NN Vector Index | Inverted Index |
Latency | Very Low | Moderate | Low |
The table above illustrates the trade-offs between different AI in e-Commerce search architectures. BM25 offers precision but lacks flexibility. Dense embeddings offer flexibility but lose precision. Sparse embeddings, however, provide a middle path that maintains the strengths of both.
For companies looking to refine their digital strategy, Natural Language Processing development services can help bridge these gaps by implementing models that respect both the literal and the conceptual layers of a query.
What are Sparse Embeddings and SPLADE?
A sparse embedding is a vector where most dimensions are zero. Each non-zero dimension corresponds to an actual vocabulary word with a learned importance weight. This provides the precision of keyword search with the flexibility of semantic understanding, a cornerstone of modern AI in e-Commerce.
The Core Mechanism of SPLADE
SPLADE (Sparse Lexical and Expansion) uses a transformer architecture to process text. It applies a masked language model head to generate output. A key feature is log saturation, which prevents any single term from dominating the vector. For a query like noise canceling headphones, the model weights headphones and noise highly while ignoring generic terms like ‘best.’
Automatic Query Expansion
SPLADE performs query expansion without manual rules. It learns from millions of pairs that summer dress relates to sundress and cotton. This shifts search management from manual synonym maintenance to data-driven discovery, optimizing the ROI of AI in e-Commerce.
Merchandising Interpretability
Because sparse vectors use real words, merchandising teams can inspect the model. If a search for running shoes shows too many socks, teams can see exactly how the running dimension is being weighted. This level of control is essential for any machine learning services intended for a high-stakes retail environment.
The shift toward these models is part of a broader trend in deep learning services. As AI becomes more ubiquitous, the focus is moving from simple automation to intelligent orchestration, where models are tailored to specific business contexts rather than being generic tools.
The 29% Lift: Benchmark Evidence
To measure success, we use the Amazon Shopping Queries Dataset (ESCI), containing 1.2 million query-product pairs. The metric used is nDCG@10 (Normalized Discounted Cumulative Gain), where 1.0 is a perfect ranking.
Model | nDCG@10 | vs BM25 |
|---|---|---|
BM25 (Baseline) | 0.305 | — |
SPLADE (Off-the-shelf) | 0.326 | +7.2% |
SPLADE (Fine-tuned) | 0.389 | +27.5% |
Fine-tuning for the specific retail domain leads to transformative gains. A ~28% improvement often moves the intended product from page two to the top of page one.
These benchmarks prove that customized AI in e-Commerce solutions far outperform generic, one-size-fits-all models.
Cross-Domain Validation:
A common question is whether a model trained on Amazon data can work for other retailers.
Results remained consistent across other datasets, showing a +7.9% gain for Wayfair and +10.0% for Home Depot over BM25.
Interestingly, research shows that hybrid search (combining sparse and dense) can actually dilute performance in specialized retail environments by introducing semantically similar but irrelevant noise.
This suggests that for high-performance AI in e-Commerce, a specialist model is often superior to a generalist hybrid.
A 29% improvement in search quality is not a marginal gain. Search visitors generatea significant part of revenue and improving the accuracy of those results directly affects click-through rates and add-to-cart rates.
For business owners, this is an opportunity to reclaim revenue that is currently being lost to technical inefficiency.
If you are curious about what a 29% improvement would look like for your catalog, speaking with an AI/ML solutions expert can help clarify the potential ROI.
Ready to stop leaving conversions on the table?
MoogleLabs has built ML-powered search, recommendation, and NLP systems for clients across e-commerce, retail, and logistics.
If you are a decision-maker evaluating whether sparse embedding fine-tuning is the right investment for your AI in e-Commerce search infrastructure, we can help you scope the opportunity, starting with a no-commitment discovery call.
The Fine-Tuning Pipeline
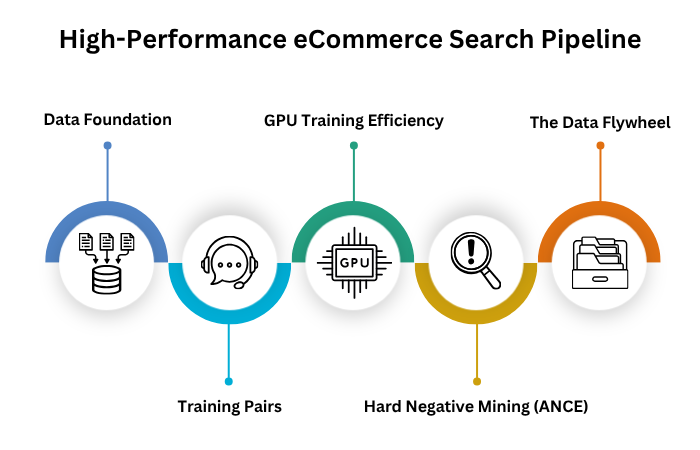
The implementation of a high-performance search model follows a structured pipeline. The implementation of a high-performance search model follows a structured pipeline. For those deploying AI in e-Commerce, the workflow is remarkably cost-effective.
1. Data Foundation:
Use product titles, brands, and bullet points. Clean data engineering ensures the model learns from high-quality signals. This stage highlights the value of clean data engineering to ensure the model has a clear foundation for learning.
2. Training Pairs:
Training requires pairs of queries and products. Use click log data or generate synthetic queries for cold-start scenarios. In case of limited data, generative AI services can be used to imagine what customers might search for, creating a synthetic training set that mimics real behavior.
3. GPU Training Efficiency:
Training a model on 100,000 query-product pairs takes approximately six minutes on an A100 GPU, costing under $1 on serverless infrastructure. Even the massive 1.2 million pair Amazon dataset can be trained in just a few hours. There is no need for expensive, idle hardware. Modern cloud platforms allow for pay-per-second training. This accessibility has democratized high-performance AI in e-Commerce for smaller retailers
4. Hard Negative Mining (ANCE):
The model improves by looking at its own mistakes. Through a process called ANCE (Approximate Nearest Neighbor Negative Contrastive Estimation), the model identifies products it ranks highly that are not actually relevant. Training on these hard negatives forces the model to learn the fine distinctions between similar items. For example, the difference between two distinct models of the same brand of headphones.
5. The Data Flywheel
Learning about the distinction between similar items creates a data flywheel. It includes creating a better model, leading to better ranking, resulting in more clicks, that turn into better training signals, eventually letting you build and even better models.
This proprietary data is a competitive asset that belongs only to your business. It powers a virtuous cycle, which is the ultimate goal of implementing AI in e-Commerce at scale
Should You Fine-Tune? A Decision Framework for e-Commerce Teams in 2026
The decision to invest in fine-tuning depends on the scale of your operation and the complexity of your catalog. In 2026, AI in e-Commerce has matured to the point where there are clear paths for different types of businesses and every budget.
Decision matrix for implementation
Strategic implementation paths for AI in e-Commerce based on data maturity and catalog size:
Your Situation | Recommended Approach | Expected Gain vs BM25 |
|---|---|---|
Single retailer, large catalog, click data available | Domain-specific fine-tuning | +25% to +30% |
Marketplace / Multi-retailer platform | Multi-domain training | +15% to +22% |
New store, limited data, limited budget | Off-the-shelf SPLADE (v3) | +7% to +10% |
Hybrid (Product search + Editorial content) | Multi-domain with regularization | Varies |
The requirements for starting are straightforward: structured product data (at minimum title and brand), either click logs or an LLM for synthetic queries, and a vector database that natively supports sparse vectors.
For many decision-makers, an Artificial Intellgence services company can help determine which of these paths offers the best return for their specific goals. Engaging with machine learning consulting can provide a roadmap from your current state to a high-conversion search infrastructure.
From Model to Production: What Implementation Actually Looks Like
Moving a model from the training phase to a live production environment requires careful planning regarding speed and reliability. In a real-world scenario, customers expect a search experience that feels instantaneous. Scaling AI in e-Commerce requires balancing this speed with model depth.
Latency and Performance Profiles
The total query latency for a sparse embedding system typically falls between 10 and 20 milliseconds. Most of this time is spent in the transformer encoding phase, while the actual retrieval from the index takes less than 1 millisecond.
This retrieval step is negligible compared to the overall page load time.
For high-volume stores, further optimizations like model distillation can increase speed by 5 to 10 times with only a minor impact on quality.
The MLOps Layer for Long-Term Success
A search model is not a one-time deployment. It is a living part of your infrastructure. It requires a robust MLOps services layer to monitor performance.
This includes tracking recall to ensure new products are surfacing correctly, monitoring latency, and setting triggers for retraining when seasonal vocabulary shifts. If a clothing store suddenly stocks cottagecore fashion, the model needs to be updated to recognize that new trend.
Implementation timeline for 2026
Data Preparation (1-2 weeks): Organizing catalog data and training pairs.
Initial Training (days): Running the GPU-based training pipeline.
Evaluation and Iteration (1-2 weeks): Testing the model against benchmarks.
MLOps and Deployment (2-4 weeks): Setting up monitoring and A/B testing.
Total time for a first deployment is usually 6 to 10 weeks. Subsequent retraining cycles are shorter and often automated.
This structured approach ensures that the system is reliable and safe for industry-standard use.
When considering AI testing services, it is important to include stress tests and bias audits to ensure the search results remain fair and accurate.
Recovering Thousands in Lost Sales Through Search & Trust
Search is a revenue recovery tool. By reducing zero results through query expansion, merchants reclaim lost income. Furthermore, accurate search leverages social proof; if the most relevant, highly-rated product appears first, conversion rates can jump by up to 50% over the site average.
AI TRiSM and Safety
Frameworks like AI TRiSM (Trust, Risk, and Security Management) are becoming vital.
Sparse embeddings offer native explainability. This transparency in AI in e-Commerce is a requirement under regulations like the EU AI Act.
Implementing AI safety measures, such as deterministic guardrails and fail-safe default states, ensures that AI-driven search remains a reliable tool for professional users.
In safety-critical sectors like healthcare, this accuracy ensures users find the exact part or medication needed, rather than a close alternative.
By grounding these systems in verified data through techniques like RAG (Retrieval-Augmented Generation), companies can prevent the hallucinations that plague less sophisticated models.
Technology trends: Moving toward the autonomous enterprise
The shift toward sparse embeddings is part of impactful business technology trends for 2026: the rise of agentic AI and autonomous operations. AI is moving from being a scripted assistant to an agent that can reason, plan, and execute tasks. In search, this means the system doesn't just find a product. It understands the customer's broader goal.
Agentic search and digital proxies
Gartner forecasts that agentic AI will be responsible for a significant portion of enterprise software revenue in the coming decade.
These systems can autonomously reroute orders, adjust inventory reorder points, and handle complex customer support resolutions.
A search engine that can bridge the vocabulary gap and understand exact attributes is the fundamental retrieval layer for these autonomous agents, marking the next phase of AI in e-Commerce.
Sovereign AI and data mesh
Many businesses are moving away from centralized data lakes toward a data mesh architecture, where individual units manage their data as a product. This allows for more specialized models that are hosted within private clouds to ensure AI sovereignty and data privacy.
For an e-commerce retailer, this means owning the search model and the data that fuels it, creating a unique asset that competitors cannot replicate. This localized approach to AI in e-Commerce ensures data privacy while maintaining peak performance.
Conclusion – Reclaiming the 40% Revenue Gap
The evidence from benchmarks and production deployments shows that AI in e-commerce search is often the most undervalued asset on a retail site. While it drives up to 60% of conversions, it is frequently the last place companies look for innovation. By adopting sparse embeddings and SPLADE, retailers can solve the two biggest problems in search: the vocabulary gap and attribute blur.
MoogleLabs has delivered over 160 AI solutions with 97% retention rate, across diverse industries, from healthcare to logistics. Our expertise in AI/ML solutions and AI consulting services allows us to help businesses navigate the shift toward modern search architectures.
We understand that for a decision-maker, the goal is not just to have AI in e-Commerce, but to have a system that measurably improves the bottom line.
If your store suffers from high abandonment or zero results, your technology is falling behind. The first step to reclaiming your revenue is ensuring your customers find exactly what they seek.
Explore our case studies to see how we transform digital retail.
Loading FAQs
Please wait while we fetch the questions...