Building Multi-Agent Systems Using Machine Learning Models

Learn how multi-agent machine learning architectures replace monolithic AI with distributed, autonomous systems that deliver scalable, resilient, and enterprise-ready automation.
Routing enterprise workloads through a single centralized model prompt introduces severe execution bottlenecks. Monolithic large language model (LLM) deployments suffer from compounding latency, rapidly inflating token costs, and prompt degradation when forced to manage more than a dozen tool integrations simultaneously.
As functional requirements scale, a single reasoning context undergoes structural breakdown due to context-window pollution and attention degradation. Production-grade machine learning services demand a paradigm shift toward decentralized software topology. Building high-performance software systems requires decoupling complex business objectives into isolated, deterministic tasks that are executed by a network of specialized, autonomous nodes.
Through enterprise-scale machine learning development, organizations deploy multi-agent systems that replace fragile, single-point-of-failure pipelines with scalable, self-healing network configurations.
Technical Deconstruction of Multi-Agent Topologies
A multi-agent system functions as an asynchronous, distributed execution graph where independent software entities or autonomous AI agents interact via structured protocols to achieve a macro-objective. Within a production system designed by an experienced engineering organization, each agent operates as an isolated execution runtime comprising of a core reasoning engine, explicit tool schemas, localized state registers, and dedicated memory tiers.
Mathematical and Operational Characteristics
State Isolation: Agents maintain absolute control over their internal execution loops. External mutations occur exclusively through formalized message passing, preventing corruption of shared memory across parallel threads.
Asynchronous Execution: System architectures decouple operations by allowing agents to process localized inputs concurrently, eliminating the blocking bottlenecks inherent in linear workflow scripts.
Dynamic Routing: Instead of relying on hardcoded programmatic paths, execution trajectories adapt dynamically as AI agents evaluate downstream outputs against localized validation parameters.
Distributed Consensus: Complex environments utilize decentralized validation nodes to cross-verify agent outputs before updating core relational databases.
Structural Performance Analysis: Monolithic vs. Multi-Agent Systems
Monolithic systems process entire operations inside a unified prompt space. This design requires the model to perform intent classification, state tracking, schema parsing, and execution mapping within a single context window.
As input payload sizes grow, the underlying model experiences exponential degradation in tool-calling accuracy, alongside proportional latency inflation. Distributed agent architectures split these responsibilities into distinct sub-graphs. A dedicated supervisor agent identifies the root objective and delegates isolated sub-tasks to specialized worker nodes.
Each worker node operates with a highly stripped system prompt and a minimal set of tools, maintaining low token consumption and near-zero tool-calling error rates. Optimizing these prompt interfaces relies heavily on structured methodologies outlined in prompt engineering in modern machine learning.
Algorithmic Architecture of Multi-Agent Machine Learning
Moving past basic API wrapping requires deep integration with advanced multi-agent machine learning paradigms. Deploying autonomous networks requires structuring precise reward models, semantic communication loops, and distributed training mechanics.
Multi-Agent Reinforcement Learning (MARL) Implementation
MARL handles non-stationary environments in which multiple agents simultaneously alter system states, rendering single-agent RL algorithms ineffective. Production architectures rely on Centralized Training with Decentralized Execution (CTDE).
During optimization, a centralized value function evaluates joint action spaces to solve the credit assignment problem and identify the precise action driving systemic success. At runtime, individual nodes execute policies independently using local observation vectors, preserving low-latency inference speeds.
Semantic Schema Integration and Protocol Serialization
Production networks replace unstructured text parsing with strict typing contracts to enforce boundaries between nodes. Agents serialize internal reasoning states into standardized formats like JSON schemas or binary Protocol Buffers before transmission.
The receiving node validates these incoming data structures against local validation classes, isolating the reasoning engine from formatting exceptions and erratic text outputs.
Privacy-Preserving Federated Training
For highly regulated industries like fintech and healthcare, federated learning protocols eliminate data centralization risks. Edge nodes train localized models independently on isolated private servers.
Upon cycle completion, these servers transmit only optimized mathematical weights and gradient updates via secure TLS to a central coordinator. The coordinator runs aggregation algorithms, such as Federated Averaging, to refine the global asset without exposing raw compliance data.
The Five Structural Pillars of Enterprise Agent Frameworks
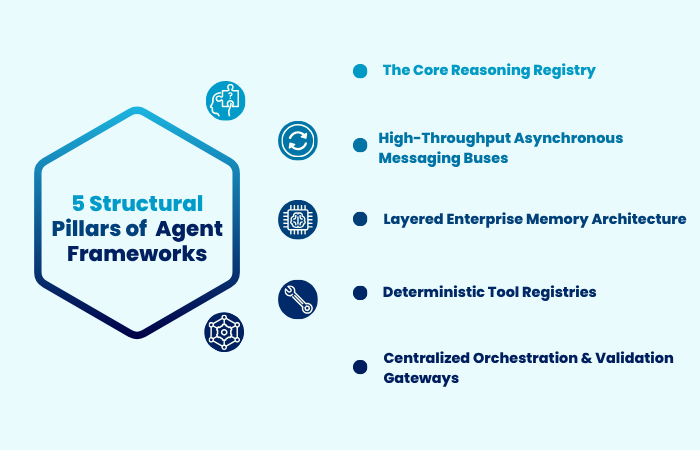
Building operational resilience into an enterprise multi-agent deployment requires a highly organized system architecture structured around five specific technical layers.
1. The Core Reasoning Registry
The reasoning registry manages individual agent identities, system instructions, and structural permissions. Rather than deploying identical large language models across the entire infrastructure, optimized deployments allocate models more specifically. High-overhead, long-context models are reserved for supervisor orchestration nodes, while lean, task-specific small language models drive processing and data-extraction agents. This deployment of lightweight models reflects the growing implementation of tiny machine learning services for localized execution.
2. High-Throughput Asynchronous Messaging Buses
Direct HTTP mesh networks between agents lack the fault tolerance required for production operations. Resilient architectures deploy event-driven messaging layers using Apache Kafka, Pulsar, or RabbitMQ. Agents publish execution events to specific partitioned message topics, allowing downstream worker nodes to consume payloads asynchronously, handle temporary network disconnects via persistent consumer offsets, and scale processing throughput via parallel consumer groups.
3. Layered Enterprise Memory Architecture
Agent networks utilize a tiered memory approach to manage historical execution context without driving up infrastructure costs:
Memory Tier | Underlying Tech Stack | Operational Lifecycle | Primary Objective |
|---|---|---|---|
Short-Term Ephemeral | Redis Cache / In-Memory State | Single Session Execution | Maintaining prompt thread history during active loops |
Long-Term Relational | PostgreSQL / Neo4j | Multi-Session Lifecycle | Storing relational user profiles and organizational entities |
Semantic Knowledge | Qdrant / Milvus Vector Storage | Persistent System Storage | Supplying low-latency RAG injection payloads |
4. Deterministic Tool Registries
Agents interface with the physical software environment through a centralized tool registry. Every connected tool, whether an internal REST endpoint, a database connector, or a shell-execution sandbox, must be documented with explicit parameters and data schemas. The registry enforces strict runtime validation gates, mapping natural language execution payloads into type-safe code calls before transmission to underlying APIs.
5. Centralized Orchestration and Validation Gateways
The orchestrator tracks global execution lineages and manages multi-agent state machines. This component acts as a deterministic firewall, intercepting state modifications from worker agents, evaluating outputs against system policies, and checking for non-terminating loops before advancing the execution graph.
Technical Evaluation of Orchestration Frameworks
Selecting the foundational codebase for an enterprise AI agent development pipeline requires a rigorous assessment of structural paradigms against production performance requirements.
LangGraph: Advanced Cyclic State Management
LangGraph treats multi-agent workflows as stateful, explicit graphs. It models every agent interaction as a node, with data handoffs serving as edges.
Engineering Advantages: Built-in persistence layers enable deep-state checkpointing. This architecture enables multi-tier time-travel debugging, allowing developers to rewind execution histories to exact node states. It natively accommodates manual verification checkpoints, pausing graph execution until an external API call or human sign-off clears the state gate.
Production Limitations: The explicit definition requirement results in steep configuration overhead for highly dynamic, open-ended workflows where execution paths cannot be fully mapped in advance.
CrewAI: Hierarchical, Process-Driven Task Execution
CrewAI wraps agents into cohesive operational units, managing task execution through linear or structured hierarchical pipelines.
Engineering Advantages: Fast initialization patterns make it excellent for automating process-driven agentic AI workflows such as corporate content generation, data extraction, and automated software testing pipelines. It minimizes boilerplate code by standardizing role definitions and tool access patterns.
Production Limitations: Complex cyclic loops and long-running, multi-layered agent interactions frequently strain its structural state engine, making it less suitable for non-linear systems.
AutoGen: Open-Ended Conversational Architecture
Developed with a focus on conversation-driven multi-agent problem-solving, AutoGen excels at orchestrating flexible, multi-model interactions.
Engineering Advantages: Native support for diverse conversational topographies allows developers to build fluid, open-ended problem-solving setups where models can chat dynamically to resolve code blocks.
Production Limitations: The lack of strict, deterministic state boundaries makes it prone to unpredictable execution paths and token consumption spikes if left without custom structural guardrails in enterprise environments.
Production Pipeline: Engineering an Agent Deployment
Transforming abstract code into a resilient production asset requires an end-to-end MLOps pipeline built on structured engineering principles.
Objective Isolation and Decomposition
Analyze the target business operations to map out execution steps. Dissect the flow to separate activities requiring probabilistic machine learning evaluations from those handled by traditional, deterministic code. If a step involves querying a specific database index or applying a fixed mathematical formula, route it through an optimized microservice rather than assigning it to an AI agent.
Model Provisioning and Fine-Tuning
Avoid routing simple, repetitive extraction or classification tasks to expensive, high-latency frontier models. Provision a tiered model array. Fine-tune local small language models on narrow enterprise datasets to handle targeted formatting, schema extraction, and verification tasks. Aligning these specialized models requires an operational grasp of core architectures, as detailed in this breakdown of transformers in machine learning.
Contract Enforcement and Schema Design
Bind all agent inputs and outputs to strict validation schemas. Every message topic payload passed across your messaging bus must conform to a defined type blueprint. Enforcing these input/output schemas prevents downstream logic breaks when models output erratic or malformed strings under heavy production traffic.
Runtime Sandboxing and Infrastructure Isolation
Agents granted code-generation or file-system execution privileges present a high-risk security vector. Enforce absolute zero-trust parameters by decoupling tool runtimes from your primary application infrastructure. Deploy code-executing nodes within isolated, hardened kernel containers or microVM architectures like gVisor or AWS Firecracker, applying strict egress network filtering to block unauthorized data exfiltration.
Continuous MLOps and Behavioral Observability
Agent interactions can alter system state paths unpredictably when foundational model checkpoints are updated. Implement continuous evaluation pipelines that run automated benchmark tests against live agent logs. Track execution paths, monitor token-burn velocities, tool execution success rates, and real-time semantic drift across all deployed node clusters.
Production Safety, Guardrails, and Mitigation Strategies
Deploying decentralized intelligence introduces structural failure modes that require automated, low-latency mitigation strategies.
Managing Non-Terminating Infinite Loop Cycles
When two or more agents fail to parse each other’s data outputs, they can drop into an infinite loop, continuously re-transmitting malformed payloads, and driving up operational costs.
Mitigation Strategy: Implement state signature monitoring inside the orchestrator engine. The orchestrator hashes the execution payload and context state at each step. If an identical state hash signature appears more than a set number of times within an execution branch, the orchestrator kills the loop, triggers a state rollback, and alerts an on-call engineer via webhook.
Mitigating Cascading Model Failures
A minor data formatting variation or drift in an upstream agent's output can compound as it travels across the network, leading to system-wide failures down the line.
Mitigation Strategy: Build isolated validation gates between agent handoff boundaries. Every intermediate payload must clear automated parsing checks before it can land on a downstream message topic. If an output fails validation, the orchestrator isolates the payload, drops the specific execution path, and initiates localized self-correction steps by prompting the source agent with the explicit validation error log.
Driving Enterprise Automation with MoogleLabs
Enterprise operations are transitioning away from assistive interfaces toward autonomous digital workforces driven by deep machine learning development. Maximizing return on investment requires building modular, decoupled architectures from day one.
By designing multi-agent networks around explicit type validation schemas, asynchronous event infrastructure, and hardened runtime security loops, technology organizations scale automated processes safely and cost-effectively.
MoogleLabs delivers the precise engineering expertise required to deploy production-ready multi-agent systems. Through specialized AI/ML services, our engineering teams optimize token expenditure with fine-tuned small language models and enforce zero-trust security with sandboxed microVM runtimes.
Deploying highly observable, self-correcting configurations through MoogleLabs provides tech leaders with the infrastructure necessary to implement the best AI agent pipelines, protecting core business interests and driving long-term operational scale.
Loading FAQs
Please wait while we fetch the questions...